
Διπλότυπο περιεχόμενο
Τι είναι το διπλό περιεχόμενο;
Το διπλό περιεχόμενο είναι περιεχόμενο που εμφανίζεται στο Διαδίκτυο σε περισσότερα από ένα μέρη. Αυτό το “ένα μέρος” ορίζεται ως μια τοποθεσία με μια μοναδική διεύθυνση ιστότοπου ( URL ) – επομένως, εάν το ίδιο περιεχόμενο εμφανίζεται σε περισσότερες από μία διευθύνσεις ιστού, έχετε διπλό περιεχόμενο.
Αν και δεν είναι τεχνικά πρόστιμο , το διπλό περιεχόμενο μπορεί μερικές φορές να επηρεάσει την κατάταξη των μηχανών αναζήτησης. Όταν υπάρχουν πολλά κομμάτια, όπως το αποκαλεί η Google , “αισθητά παρόμοιο” περιεχόμενο σε περισσότερες από μία τοποθεσίες στο Διαδίκτυο, μπορεί να είναι δύσκολο για τις μηχανές αναζήτησης να αποφασίσουν ποια έκδοση είναι πιο σχετική με ένα δεδομένο ερώτημα αναζήτησης.
Γιατί έχει σημασία το διπλό περιεχόμενο;
Για μηχανές αναζήτησης
Το διπλό περιεχόμενο μπορεί να παρουσιάσει τρία βασικά ζητήματα για τις μηχανές αναζήτησης:
- Δεν γνωρίζουν ποιες εκδόσεις πρέπει να συμπεριληφθούν / εξαιρούνται από τους δείκτες τους.
- Δεν ξέρουν αν θα κατευθύνουν τις μετρήσεις συνδέσμου (εμπιστοσύνη, αρχή, κείμενο αγκύρωσης ,συνδέστε τα ίδια κεφάλαια , κ.λπ.) σε μία σελίδα ή διατηρήστε τη διαχωρισμένη μεταξύ πολλών εκδόσεων.
- Δεν ξέρουν ποιες εκδόσεις θα κατατάξουν για αποτελέσματα ερωτημάτων.
Για κατόχους ιστότοπων
Όταν υπάρχει διπλό περιεχόμενο, οι ιδιοκτήτες ιστότοπων ενδέχεται να υποστούν κατάταξη και απώλεια επισκεψιμότητας. Αυτές οι απώλειες προέρχονται συχνά από δύο κύρια προβλήματα:
- Για να παρέχουν την καλύτερη εμπειρία αναζήτησης, οι μηχανές αναζήτησης σπάνια θα εμφανίζουν πολλές εκδόσεις του ίδιου περιεχομένου, και ως εκ τούτου αναγκάζονται να επιλέξουν ποια έκδοση είναι πιθανότερο να είναι το καλύτερο αποτέλεσμα. Αυτό αραιώνει την ορατότητα καθενός από τα διπλά.
- Το Equity Link μπορεί να αραιωθεί περαιτέρω, επειδή και άλλοι ιστότοποι πρέπει να επιλέξουν μεταξύ των διπλότυπων. Αντί για όλους τους εισερχόμενους συνδέσμους που δείχνουν ένα κομμάτι περιεχομένου, συνδέονται σε πολλά κομμάτια, διαδίδοντας το δίκαιο του συνδέσμου μεταξύ των διπλών. Επειδή οι εισερχόμενοι σύνδεσμοι αποτελούν παράγοντα κατάταξης , αυτό μπορεί στη συνέχεια να επηρεάσει την ορατότητα αναζήτησης ενός κομματιού περιεχομένου.
Το καθαρό αποτέλεσμα; Ένα κομμάτι περιεχομένου δεν επιτυγχάνει την ορατότητα της αναζήτησης, διαφορετικά.

Πώς συμβαίνουν ζητήματα διπλού περιεχομένου;
Στη συντριπτική πλειονότητα των περιπτώσεων, οι κάτοχοι ιστότοπων δεν δημιουργούν σκόπιμα διπλό περιεχόμενο. Όμως, αυτό δεν σημαίνει ότι δεν είναι εκεί έξω. Στην πραγματικότητα, από ορισμένες εκτιμήσεις, έως και το 29% του ιστού είναι στην πραγματικότητα διπλό περιεχόμενο!
Ας ρίξουμε μια ματιά σε μερικούς από τους πιο συνηθισμένους τρόπους δημιουργίας διπλού περιεχομένου κατά λάθος:
1. Παραλλαγές URL
Οι παράμετροι διεύθυνσης URL, όπως η παρακολούθηση κλικ και κάποιος κώδικας αναλυτικών στοιχείων, μπορούν να προκαλέσουν διπλά προβλήματα περιεχομένου. Αυτό μπορεί να είναι ένα πρόβλημα που προκαλείται όχι μόνο από τις ίδιες τις παραμέτρους, αλλά και από τη σειρά με την οποία εμφανίζονται αυτές οι παράμετροι στην ίδια τη διεύθυνση URL.
Για παράδειγμα:
- Το www.widgets.com/blue-widgets?c … είναι διπλότυπο του www.widgets.com/blue-widgets?c … & cat = 3 “class =” redactor-autoparser-object “> www.widgets. com / blue-widgets είναι ένα αντίγραφο του www.widgets.com/blue-widgets ? cat = 3 & color = blue
Ομοίως, τα αναγνωριστικά περιόδου σύνδεσης είναι ένας κοινός δημιουργός διπλού περιεχομένου. Αυτό συμβαίνει όταν σε κάθε χρήστη που επισκέπτεται έναν ιστότοπο έχει ένα διαφορετικό αναγνωριστικό περιόδου σύνδεσης που είναι αποθηκευμένο στη διεύθυνση URL.

Οι εκδόσεις περιεχομένου που είναι φιλικές προς τον εκτυπωτή μπορούν επίσης να προκαλέσουν διπλά ζητήματα περιεχομένου όταν ευρετηριάζονται πολλές εκδόσεις των σελίδων.

Ένα μάθημα εδώ είναι ότι, όταν είναι δυνατόν, είναι συχνά χρήσιμο να αποφεύγετε την προσθήκη παραμέτρων URL ή εναλλακτικών εκδόσεων διευθύνσεων URL (οι πληροφορίες που περιέχουν μπορούν συνήθως να περάσουν μέσω σεναρίων).
2. HTTP εναντίον HTTPS ή WWW έναντι σελίδων εκτός WWW
Εάν ο ιστότοπός σας έχει ξεχωριστές εκδόσεις στα “www.site.com” και “site.com” (με και χωρίς το πρόθεμα “www”) και το ίδιο περιεχόμενο ζει και στις δύο εκδόσεις, έχετε δημιουργήσει αποτελεσματικά διπλά από καθένα από αυτά σελίδες. Το ίδιο ισχύει και για ιστότοπους που διατηρούν εκδόσεις τόσο σε http: // όσο και σε https: //. Εάν και οι δύο εκδόσεις μιας σελίδας είναι ζωντανές και ορατές στις μηχανές αναζήτησης, ενδέχεται να αντιμετωπίσετε ένα διπλό ζήτημα περιεχομένου.
3. Περιεχόμενο που έχει αντιγραφεί ή αντιγραφεί
Το περιεχόμενο περιλαμβάνει όχι μόνο αναρτήσεις ιστολογίου ή περιεχόμενο σύνταξης, αλλά και σελίδες πληροφοριών προϊόντων. Τα Scraper που αναδημοσιεύουν το περιεχόμενο του ιστολογίου σας στους δικούς τους ιστότοπους μπορεί να είναι μια πιο οικεία πηγή διπλού περιεχομένου, αλλά υπάρχει και ένα κοινό πρόβλημα για ιστότοπους ηλεκτρονικού εμπορίου: πληροφορίες προϊόντος. Εάν πολλοί διαφορετικοί ιστότοποι πωλούν τα ίδια αντικείμενα και όλοι χρησιμοποιούν τις περιγραφές του κατασκευαστή αυτών των στοιχείων, το ίδιο περιεχόμενο καταλήγει σε πολλές τοποθεσίες στον ιστό.
Τρόπος επίλυσης προβλημάτων διπλού περιεχομένου
Η επίλυση ζητημάτων διπλού περιεχομένου βασίζεται στην ίδια κεντρική ιδέα: καθορίζοντας ποιο από τα διπλότυπα είναι το “σωστό”.
Κάθε φορά που περιεχόμενο σε έναν ιστότοπο μπορεί να βρεθεί σε πολλές διευθύνσεις URL, θα πρέπει να κανονικοποιείται για μηχανές αναζήτησης. Ας δούμε τους τρεις βασικούς τρόπους για να το κάνουμε αυτό: Χρησιμοποιώντας μια ανακατεύθυνση 301 στη σωστή διεύθυνση URL, το χαρακτηριστικό rel = canonical ή χρησιμοποιώντας το εργαλείο χειρισμού παραμέτρων στο Google Search Console.
Ανακατεύθυνση 301
Σε πολλές περιπτώσεις, ο καλύτερος τρόπος για την καταπολέμηση του διπλού περιεχομένου είναι να δημιουργήσετε μια ανακατεύθυνση 301 από τη σελίδα “διπλότυπο” στην αρχική σελίδα περιεχομένου.
Όταν πολλές σελίδες με δυνατότητα κατάταξης συνδυάζονται σε μία σελίδα, δεν σταματούν μόνο να ανταγωνίζονται μεταξύ τους. δημιουργούν επίσης ένα ισχυρότερο σήμα συνάφειας και δημοτικότητας συνολικά. Αυτό θα επηρεάσει θετικά την ικανότητα της “σωστής” σελίδας να βαθμολογεί καλά.

Rel = “κανονικό”
Μια άλλη επιλογή για την αντιμετώπιση διπλού περιεχομένου είναι να χρησιμοποιήσετε το χαρακτηριστικό rel = canonical . Αυτό λέει στις μηχανές αναζήτησης ότι μια δεδομένη σελίδα θα πρέπει να αντιμετωπίζεται σαν να ήταν αντίγραφο μιας καθορισμένης διεύθυνσης URL και όλοι οι σύνδεσμοι, οι μετρήσεις περιεχομένου και η “ισχύς κατάταξης” που εφαρμόζουν οι μηχανές αναζήτησης σε αυτήν τη σελίδα πρέπει να πιστώνονται στην καθορισμένη Διεύθυνση URL.

Το χαρακτηριστικό rel = “canonical” είναι μέρος της κεφαλίδας HTML μιας ιστοσελίδας και μοιάζει με αυτό:
Γενική μορφή:
<head> ... [άλλος κώδικας που μπορεί να υπάρχει στην κεφαλή HTML του εγγράφου σας] ... <link href = "URL της αρχικής σελίδας" rel = "canonical" /> ... [άλλος κωδικός που μπορεί να υπάρχει στα έγγραφά σας Κεφαλή HTML] ... </head>
Το χαρακτηριστικό rel = canonical πρέπει να προστεθεί στην κεφαλή HTML κάθε διπλής έκδοσης μιας σελίδας, με το τμήμα “URL της αρχικής σελίδας” να αντικατασταθεί από έναν σύνδεσμο προς την αρχική (κανονική) σελίδα. (Βεβαιωθείτε ότι διατηρείτε τα εισαγωγικά.) Το χαρακτηριστικό περνά περίπου το ίδιο ποσό ιδίων συνδέσμων (ισχύς κατάταξης) με την ανακατεύθυνση 301 και, επειδή εφαρμόζεται στο επίπεδο της σελίδας (αντί του διακομιστή), συχνά χρειάζεται λιγότερος χρόνος ανάπτυξης υλοποιώ, εφαρμόζω.
Ακολουθεί ένα παράδειγμα του κανονικού χαρακτηριστικού στην πράξη:
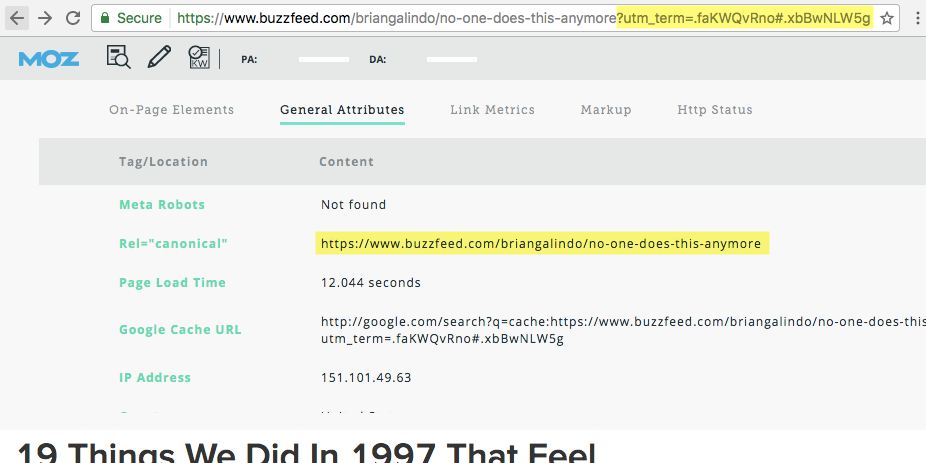
Χρησιμοποιώντας το MozBar για τον εντοπισμό κανονικών χαρακτηριστικών.
Εδώ, μπορούμε να δούμε ότι το BuzzFeed χρησιμοποιεί τα χαρακτηριστικά rel = canonical για να προσαρμόσει τη χρήση παραμέτρων URL (σε αυτήν την περίπτωση, παρακολούθηση κλικ). Αν και αυτή η σελίδα είναι προσβάσιμη με δύο διευθύνσεις URL, το χαρακτηριστικό rel = canonical διασφαλίζει ότι όλες οι μετρήσεις ιδίων συνδέσμων και περιεχομένου απονέμονται στην αρχική σελίδα (/ no-one-do-this-now).
Meta Robots Noindex
Μια μετα-ετικέτα που μπορεί να είναι ιδιαίτερα χρήσιμη για την αντιμετώπιση διπλού περιεχομένου είναι τα μετα-ρομπότ , όταν χρησιμοποιούνται με τις τιμές “noindex, follow.” Συνήθως ονομάζεται Meta Noindex, Follow και τεχνικά γνωστό ως content = “noindex, follow” αυτή η μετα-ρομπότ ετικέτα μπορεί να προστεθεί στην κεφαλή HTML κάθε μεμονωμένης σελίδας που θα πρέπει να εξαιρεθεί από το ευρετήριο μιας μηχανής αναζήτησης.
Γενική μορφή:
<head> ... [άλλος κωδικός που μπορεί να βρίσκεται στην κεφαλή HTML του εγγράφου σας] ... <meta name = "robots" content = "noindex, follow"> ... [άλλος κωδικός που μπορεί να υπάρχει στην κεφαλή HTML του εγγράφου σας ] ... </head>
Η ετικέτα μετα-ρομπότ επιτρέπει στις μηχανές αναζήτησης να ανιχνεύουν τους συνδέσμους σε μια σελίδα, αλλά τους εμποδίζει να συμπεριλάβουν αυτούς τους συνδέσμους στους δείκτες τους. Είναι σημαντικό να είναι δυνατή η ανίχνευση της διπλότυπης σελίδας, παρόλο που λέτε στην Google να μην την ευρετηριάσει, επειδή η Google προειδοποιεί ρητά να μην περιορίσει την πρόσβαση ανίχνευσης σε διπλό περιεχόμενο στον ιστότοπό σας. (Οι μηχανές αναζήτησης θέλουν να βλέπουν τα πάντα σε περίπτωση που έχετε κάνει λάθος στον κώδικά σας. Τους επιτρέπει να κάνουν μια [πιθανή αυτοματοποιημένη] “κλήση κρίσης” σε διαφορετικά αμφίσημες καταστάσεις.)
Η χρήση μετα-ρομπότ είναι μια ιδιαίτερα καλή λύση για διπλά θέματα περιεχομένου που σχετίζονται με τη σελιδοποίηση .
Προτιμώμενος χειρισμός τομέα και παραμέτρων στο Google Search Console
Το Google Search Console σάς επιτρέπει να ορίσετε τον προτιμώμενο τομέα του ιστότοπού σας (π.χ. http://yoursite.com αντί για http://www.yoursite.com) και να καθορίσετε εάν το Googlebot θα πρέπει να ανιχνεύσει διαφορετικές παραμέτρους URL διαφορετικά (χειρισμός παραμέτρων).
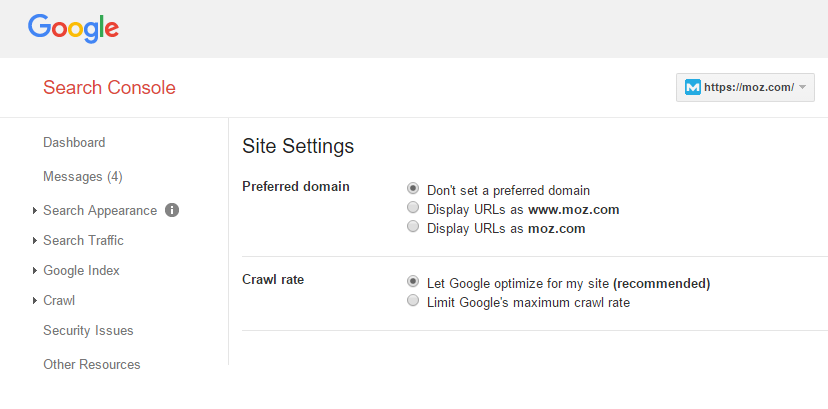
Ανάλογα με τη δομή της διεύθυνσης URL και την αιτία των ζητημάτων διπλού περιεχομένου σας, η ρύθμιση του προτιμώμενου χειρισμού τομέα ή παραμέτρων (ή και τα δύο!) Μπορεί να προσφέρει μια λύση.
Το κύριο μειονέκτημα της χρήσης παραμέτρων ως κύριας μεθόδου αντιμετώπισης διπλού περιεχομένου είναι ότι οι αλλαγές που πραγματοποιείτε λειτουργούν μόνο για την Google. Τυχόν κανόνες που εφαρμόζονται χρησιμοποιώντας το Google Search Console δεν θα επηρεάσουν τον τρόπο με τον οποίο ο Bing ή οι άλλοι ανιχνευτές μηχανών αναζήτησης ερμηνεύουν τον ιστότοπό σας. θα χρειαστεί να χρησιμοποιήσετε τα εργαλεία για webmaster για άλλες μηχανές αναζήτησης εκτός από την προσαρμογή των ρυθμίσεων στο Search Console.
Πρόσθετες μέθοδοι αντιμετώπισης διπλού περιεχομένου
- Διατηρήστε τη συνέπεια κατά την εσωτερική σύνδεση σε έναν ιστότοπο. Για παράδειγμα, εάν ένας webmaster διαπιστώσει ότι η κανονική έκδοση ενός τομέα είναι www.example.com/, τότε όλοι οι εσωτερικοί σύνδεσμοι πρέπει να μεταβούν στη διεύθυνση http: // www. example.co … αντί για http: // example.com/pa … (παρατηρήστε την απουσία του www).
- Κατά τη διανομή περιεχομένου, βεβαιωθείτε ότι ο ιστότοπος κοινοπραξίας προσθέτει έναν σύνδεσμο πίσω στο αρχικό περιεχόμενο και όχι παραλλαγή στη διεύθυνση URL. (Δείτε το επεισόδιο της Παρασκευής του Whiteboard σχετικά με την αντιμετώπιση διπλού περιεχομένου για περισσότερες πληροφορίες.)
- Για να προσθέσετε ένα επιπλέον προστατευτικό μέσο κατά των κλεψίματος περιεχομένου που κλέβουν πίστωση SEO για το περιεχόμενό σας, είναι καλό να προσθέσετε έναν αυτοαναφερόμενο σύνδεσμο rel = canonical στις υπάρχουσες σελίδες σας. Πρόκειται για ένα κανονικό χαρακτηριστικό που δείχνει τη διεύθυνση URL στην οποία βρίσκεται ήδη, με σκοπό να αποτρέψει τις προσπάθειες ορισμένων ξύστρα.

Ένας αυτοαναφερόμενος rel = κανονικός σύνδεσμος: Η διεύθυνση URL που καθορίζεται στην ετικέτα rel = κανονική είναι ίδια με την τρέχουσα διεύθυνση URL σελίδας.
Παρόλο που δεν θα μεταφερθούν όλοι οι scraper πάνω από τον πλήρη κώδικα HTML του αρχικού τους υλικού, ορισμένοι θα. Για όσους το κάνουν, η αυτοαναφερόμενη rel = κανονική ετικέτα θα διασφαλίσει ότι η έκδοση του ιστότοπού σας θα πιστωθεί ως το “πρωτότυπο” κομμάτι περιεχομένου.















